
The native search functionality in WordPress is famously—and often frustratingly—basic. For a small blog, it’s adequate. For a growing content library, an e-commerce store, or a dynamic community site, it quickly becomes a bottleneck to user experience. The limitation lies in its reliance on simple keyword matching, a traditional approach that fails to understand the meaning, intent, or context behind a user’s query.
Table of Contents
Enter Vector Search, a paradigm shift in information retrieval. Unlike traditional search, which acts like a librarian matching an exact book title, vector search behaves like an astute scholar, finding the most semantically similar concepts, even if the user and the content use entirely different phrasing. This transformative capability is no longer the exclusive domain of tech giants; it can now be integrated into your WordPress site using powerful, flexible, and most importantly, open-source stacks.
This article will explore the why and how of building a high-quality, semantic vector search engine for your WordPress content, leveraging the power of open source technologies to deliver search results that truly work.
The Semantic Deficit: Why Traditional Search Fails
To appreciate the value of vector search, we must first understand the fundamental limitation of traditional keyword search. When a user types a query like “footwear for a snowy hike,” a keyword search engine looks for exact matches of “footwear,” “snowy,” and “hike.” If an article is titled “Best Boots for Winter Trail Adventures,” the search may fail to return a relevant result, despite the content being exactly what the user is looking for. This is the semantic deficit.
Vector Search: Understanding the Meaning
Vector search overcomes this deficit by using a process called vector embedding. In this process, machine learning models (often Large Language Models or LLMs) convert your content—text, images, audio, or video—into high-dimensional numerical arrays, known as vectors.
These vectors are plotted in a mathematical space where the distance between them represents their semantic similarity. Content that is close together in this “vector space” is conceptually related.
- Query Vector: The user’s search query (“footwear for a snowy hike”) is also converted into a vector.
- Similarity Matching: The system then calculates the distance between the query vector and all the content vectors.
- Semantic Results: The closest vectors (the “nearest neighbors”) are returned as results. Because “Best Boots for Winter Trail Adventures” is semantically close to the query, it is returned, regardless of the keyword mismatch.
This shift provides numerous benefits for a content-heavy platform like WordPress:
| Feature | Traditional Keyword Search | Vector/Semantic Search |
| Matching Basis | Exact word matches (or variations using basic stemming). | Semantic meaning and context of the words/phrase. |
| Query Flexibility | Low tolerance for typos, synonyms, or paraphrasing. | High tolerance; understands natural language and intent. |
| Unstructured Data | Struggles with large blocks of text; relies on titles/tags. | Excels at understanding long-form content and hidden relationships. |
| Relevance | Often low; can return irrelevant results with keyword stuffing. | High; results are contextually accurate to user intent. |
| User Experience | Frustrating, requires precise phrasing. | Intuitive, feels conversational and intelligent. |
The Open Source Vector Search Stack for WordPress
Implementing vector search requires three primary components: an Embedding Model (to create the vectors), a Vector Database (to store and index them), and a Connector/Orchestrator (to link the database to WordPress and handle the search logic).
The beauty of the open-source landscape is the availability of mature, high-performance tools for each of these steps, allowing you to build a powerful system without vendor lock-in or recurring SaaS costs for core functionality.
1. The Vector Database (The Engine)
The core of the system, this component is specialized for storing and indexing the high-dimensional vectors and executing Approximate Nearest Neighbor (ANN) search algorithms with low latency.
| Open Source Option | Key Features for WordPress | Best For |
| OpenSearch | Full-text and vector search in one. Mature, scalable, good for hybrid search. | Large content sites that need a unified search and analytics platform. |
| Weaviate | Pure vector-native database, excellent for scale, built-in vectorization (optional). | Developers prioritizing speed, scalability, and vector-centric features. |
| Typesense | Blazing-fast, developer-friendly search engine with vector support. Easier to set up than OpenSearch. | Mid-sized sites needing a fast, low-complexity solution for hybrid search. |
| PostgreSQL + pgvector | Leverages the existing WordPress database structure with an extension. | Sites looking to minimize infrastructure sprawl and use a familiar database. |
For many WordPress developers, Typesense or PostgreSQL with pgvector offer the most practical entry points. Typesense provides a powerful search layer with excellent performance, while pgvector allows integration with the existing WordPress database, simplifying deployment.
2. The Embedding Model (The Brain)
This model converts your raw WordPress content (post titles, content bodies, custom fields) into numerical vectors. While many high-performance models are proprietary (e.g., OpenAI, Cohere), there are excellent open-source alternatives.
- Sentence Transformers (e.g., all-MiniLM-L6-v2): A family of models that are relatively small, fast, and highly effective for generating semantic embeddings from sentences and paragraphs.
- BERT/RoBERTa variants: Larger, more robust models that capture deeper semantic meaning but require more computational power for inference.
These models are typically hosted either on a self-managed server (e.g., using Python and Flask/Docker) or through a third-party service like Hugging Face, which provides an API endpoint for vector generation. Since the embedding process is not real-time (it happens when content is created or updated), a slightly slower but higher-quality model can be used.
3. The Connector and Orchestrator (The Glue)
This is the custom layer that sits between WordPress and the vector database. WordPress is primarily written in PHP, which is less common for high-performance machine learning tasks. The orchestrator must handle three key tasks:
- Ingestion: A background job (e.g., a scheduled WordPress cron job or an external worker) that detects new or updated posts. It sends the content to the embedding model API.
- Indexing: The worker receives the vector from the model and sends it, along with the corresponding Post ID and necessary metadata, to the vector database.
- Search API: When a user searches, a custom WordPress endpoint intercepts the query, sends it to the embedding model for vectorization, queries the vector database for the nearest neighbors, and uses the returned Post IDs to fetch the full post objects from the standard WordPress database for display.
While there are some nascent open-source PHP libraries (like the MySQL-Vector library) and WordPress plugins attempting to solve this, the most stable and scalable approach for an open-source stack often involves a small external service written in Python or Go to handle the embedding and database interaction, communicating with WordPress via a simple REST API or Webhook.
A Step-by-Step Open Source Implementation Plan
For a practical implementation targeting a high-performance, open-source stack, let’s focus on Typesense for the database and a Sentence Transformer model hosted in a Python environment.
Phase 1: Infrastructure and Database Setup
Install Typesense: Deploy a Typesense server, often most easily done using a Docker container.
Bashdocker run -i -p 8108:8108 -v/tmp/typesense-data:/data typesense/typesense:latest --data-dir /data --api-key=your_secure_api_key
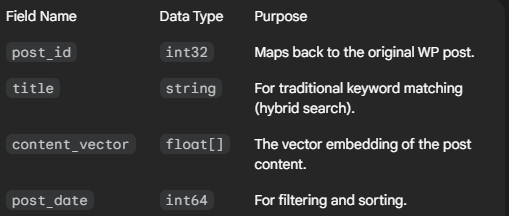
Create a Collection (Index): Define the schema in Typesense for your content.
Deploy Embedding Service: Set up a lightweight Python web service (using Flask or FastAPI) to expose an endpoint that accepts text and returns its vector embedding using your chosen Sentence Transformer model. This service acts as your internal embedding API.
Phase 2: WordPress Content Preparation and Ingestion
- The Content Worker (PHP/WP-Cron): Write a custom WordPress plugin or utilize a tool that monitors the
wp_poststable. Onsave_postor a scheduled event, the content worker prepares the text.- Text Cleaning: Remove shortcodes, excessive HTML, and boilerplate text that doesn’t contribute to semantic meaning.
- Chunking: For very long articles, split the content into smaller, semantically coherent chunks (e.g., paragraphs or groups of sentences) to get finer-grained search results. Each chunk gets its own vector.
- Vector Generation and Indexing: The worker sends the cleaned text to the external Python Embedding Service API, receives the vector array, and then sends a request to the Typesense API to index the data in the defined collection.
- Data Object for Typesense:
JSON{ "post_id": 1234, "title": "Best Boots for Winter Trail Adventures", "content_vector": [0.123, -0.456, 0.789, ...], // Your 384 or 768 dimension vector "post_date": 1672531200 }
- Data Object for Typesense:
Phase 3: Implementing the Semantic Search Frontend
- Query Interception: A custom WordPress function hooks into the default search mechanism (
pre_get_postsor a custom AJAX handler) to intercept the user’s search query. - Vector Search Execution:
- The user query is sent to the Python Embedding Service to get the query vector.
- The query vector is sent to Typesense to perform the nearest neighbor search against the
content_vectorfield. - Hybrid Search: This is where the magic happens. A truly high-quality search will combine the power of vector search with the precision of traditional keyword search (BM25 or similar) in a hybrid query. This ensures both semantic relevance and exact keyword matches are considered, often by using an algorithm like Reciprocal Rank Fusion (RRF).
- Result Retrieval and Display: Typesense returns a ranked list of
post_ids. The WordPress function uses these IDs to query the nativewp_poststable to retrieve the full post objects, which are then formatted and displayed to the user.
Advanced Enhancements and SEO Implications
Once the basic vector search is operational, you can unlock advanced capabilities that significantly enhance user experience and SEO.
1. Retrieval-Augmented Generation (RAG)
Vector search is the foundational technology for RAG, which powers sophisticated AI-driven chatbots and Q&A systems.
- Functionality: Instead of just returning a list of links, the system retrieves the most relevant content chunks (vectors) and feeds them to an LLM (e.g., an open-source model like Llama 3 running on a local server or a provider API) as context. The LLM then uses this context to generate a direct, synthesized answer for the user.
- Example: User queries, “How do I fix a WordPress white screen of death?” The RAG system finds the relevant paragraphs, passes them to the LLM, and the LLM responds with a step-by-step summary, citing the source post.
2. Semantic Content Clustering
Since all your content is now represented by vectors, you can use clustering algorithms (like k-means) to group semantically similar content.
- Internal Linking: Automatically identify the most relevant related posts to recommend for internal linking, which is a powerful signal for search engine optimization (SEO) by building topical authority.
- Content Strategy: Identify gaps in your content by finding clusters that are too sparse or, conversely, areas where you have too many overlapping, semantically redundant articles.
3. Personalized Search
User behavior (posts they read, products they view) can also be turned into a vector profile. When a user searches, their profile vector can be subtly incorporated into the query vector, biasing the results toward topics they are more likely to find relevant, leading to higher engagement.
The SEO Imperative
The shift to vector search aligns perfectly with modern SEO, which emphasizes user intent and semantic understanding over keyword density.
- Improved User Experience: Highly relevant search results reduce bounce rates and increase time-on-site, both of which are strong positive signals to search engines.
- Topical Authority: Semantic clustering and intelligent internal linking reinforce the site’s authority on core topics.
- Natural Language Processing (NLP) Readiness: By embracing vector embeddings, your content is structurally prepared for how modern search engines—which increasingly use their own vector-based models—understand and index the web. You are essentially pre-optimizing your site for the semantic web.
Building vector search on WordPress with open source tools is more than a technical upgrade; it’s a strategic move that future-proofs your content platform, transforms the user experience, and elevates your search ranking potential in the AI-driven era. While the initial setup requires more technical expertise than a simple plugin, the control, performance, and customization offered by an open-source stack deliver a superior, highly scalable solution.
